ML_Masters_Proposal-Midterm
Final Project Report
By Christine Yewon Kim, Mahika Raj, Devanshi Sood, Joseph C Miao, and Song Yue David Li
Link back to ←Proposal
Link to GitHub code: https://github.gatech.edu/mraj39/ML_Masters
Literature/Introduction/Background
In the midst of Vision and Language Navigation innovation, AerialVLN was proposed, a UAV-based VLN task for outdoor environments specifically taking into consideration aerial actions as aerial navigation is significantly more complicated than ground-based VLN [1]. However, as energy awareness is not widely discussed in VLN, the typical path-length objective of existing approaches does not directly minimize energy consumption, nor allows constraining the energy of individual paths by battery capacity [2]. We will utilize a combination of Supervised Learning and Reinforcement Learning to better consider energy, building on top of their implementation.
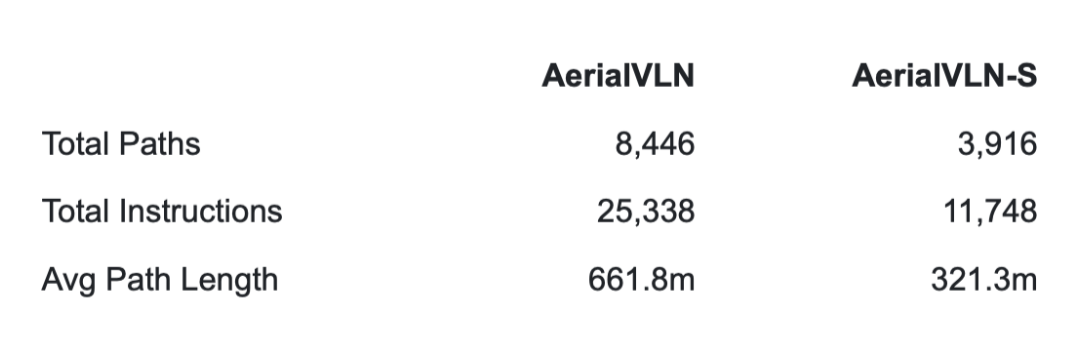
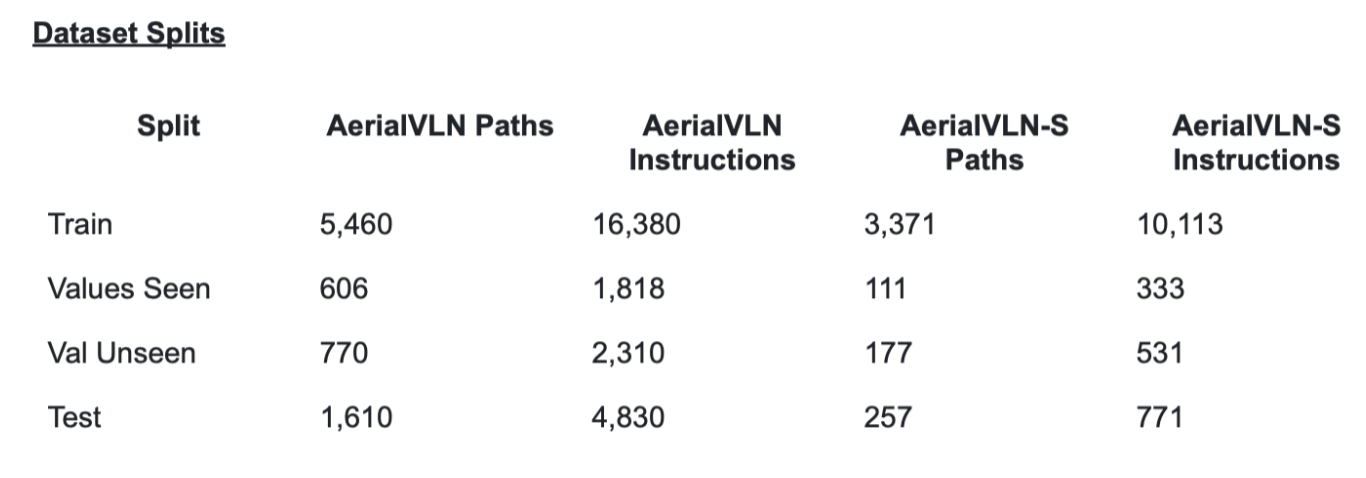
Dataset Description This Dataset includes AerialVLN and AerialVLN-S annotated images for training and evaluation, a total of 32.4GB.
Why These Dataset(s)
- AerialVLN was selected because it is the only large scale outdoor aerial VLN dataset available. Its long flight paths and complex city level environments make fuel constraints a realistic and meaningful addition to the task. Without a dataset of this scale and complexity, testing energy aware navigation would not be possible.
- Why AerialVLN-S For most of our experiments we use AerialVLN-S since the shorter average path length makes training more computationally feasible while still capturing the core challenges of the task. It also has more evenly distributed path lengths which makes evaluation more consistent.
Overview
- Total size: 32.4GB
- Built using AirSim simulator on Unreal Engine 4
- 25 city level environments (cities, factories, parks, villages)
- 870+ different object types
- Supports dynamic weather (sun, rain, snow, fog) and lighting (morning, noon, night)
- recorded by AOPA licensed human UAV pilots to ensure realistic and high quality flight trajectories. Each path is paired with 3 instructions written by Amazon Mechanical Turk workers, giving the dataset a wide variety of ways to describe the same flight.
Each Flight Data Set Contains
- Natural language instructions describing landmarks and directional cues
- Flight trajectory as a sequence of 9 discrete actions: Move Forward, Turn Left, Turn Right, Ascend, Descend, Move Left, Move Right, Stop, and the initial starting pose
- RGB and depth images from a front facing camera at every step (depth range up to 100m)
- Semantic segmentation data available for future use
Our Addition: Fuel Constraints - On top of the standard dataset, our preprocessing pipeline adds a fuel fraction at every step of every flight:
- Ranges from 1.0 (full tank) to 0.0 (empty)
- Computed dynamically during preprocessing
- Fed into the FuelGateModule during training
- Forces the model to adjust its behavior based on remaining battery level
- This addition is unique to our work and is not part of the original AerialVLN dataset
Dataset Linkzx: https://github.com/AirVLN/AirVLN
Problem: With the new constraints, specifically fuel capacity and limits, we focus on aerial navigation in the sky, UAV-based and aimed towards outdoor environments.
First step of our goal is to implement fuel constraints on our first method, Teacher Forcing, and to compare the performance of simulation without fuel constraints. This method is primarily going to be used as a baseline.
Motivation: Many existing VLN tasks are built for agents that navigate on the ground, either indoors or outdoors. However, some tasks require intelligent agents to operate in the sky, such as UAV-based goods delivery, traffic/security patrol, and scenery tours [1]. Most importantly, aerial navigation is a field with much work to be done.
Methods
Data Preprocessing Methods: The preprocessing converts the raw simulation data from the AirSim environment into a high-dimensional feature space. We distinguish between the baseline architectural encoding provided by AirVLN and our novel Fuel-Aware state implementation.
Baseline preprocessing: To manage the computational load of the AerialVLN dataset, the baseline processes the raw sensor data into optimized feature vectors using a two-stream encoding process:
- Visual Feature Extraction: The raw RGB and Depth maps are passed through a pretrailed convolutional neural network. This is done by stripping away the actual images’ spatial data and only saving the final feature vectors, representing the semantic content of the UAV images.
- Language Tokenization: The raw textual navigation instructions are processed using a tokenizer to convert natural language into numerical tokens, mapping the human readable commands into the model’s embedding space.
- Serialized packaging: These features are synchronized and packaged into high-performance binary database files to maximize the throughput during the Teacher Forcing (TF) training loop.
Dynamic Fuel Constraining: To introduce energy awareness into the navigation task, we implemented a dynamic preprocessing layer that injects space dependent constraints on the fly:
- Fuel fraction: For every discrete step within the flight trajectory, we calculate a normalized fuel fraction representing the battery life
- Mathematical formulation: This fraction is derived as the quotient of remaining mission steps over the total allocated steps: Fuel fraction[0.0, 1.0] = (Remaining steps)/(Maximum steps)
- State injection: This scalar value is appended to the visual and linguistic features at every timestep, allowing the model to perceive the remaining “survival time” relative to the goal state.
Training Methodology: The primary training methodology used is Teacher Forcing. Teacher forcing is a supervised learning algorithm that is useful in sequential models, such as navigation problems. It trains the model by taking the ground-truth as the input to the next step instead of using the predicted action. This allows the model to maintain stability, avoiding accumulation of error.
In the original implementation of AerialVLN, a dataset of pre-planned trajectories represents the ground-truth, including expected camera data, navigation instructions, and actions. It attempts up to a maximum action limit. At each step, it passes the pixels from images and depth observations through the Seq2Seq policy, along with the previous ground-truth action and current hidden state of the RNN, to output a probability distribution of actions.
The primary training objective is an imitation loss, where the trainer computes the primary loss by comparing the network’s predicted actions against the ground-truth action. Thus, Teacher Forcing encourages the model to imitate the expert trajectories, which is critical for a fuel-constrained drone.
Model Architectures: The 2 ML models that we explored are Seq2Seq and CMA (Cross Modal Alignment).
Seq2Seq is an encoder-decoder framework that works with a recurrent policy. For AerialVLN, the encoder takes in the text instruction and sensor inputs and decodes it into a probability distribution over the action space. The Seq2Seq model proceeds with the action with the highest probability.
The CMA architecture is an attention-based fusion algorithm that uses a mathematical attention mechanism to align visual features from the camera to specific text tokens at each time step. It relies on a LSTM that splits the process into a part that tracks visual observations and another that makes decisions. These features concatenate its priorities with the sensor inputs as the input to the recurrent network to predict the next action.
Fuel Constraints
Our extension of the models involves the incorporation of fuel constraints. We introduced fuel awareness as an additional input to guide the decision making process. As discussed in the pre-processing section, the fuel constraint is defined as the ratio of steps remaining to the maximum steps: it is a continuous variable from 0.0 to 1.0, where 0.0 represents no fuel remaining.
Remaining Steps / Max Steps = Fuel Fraction [0.0 - 1.0]
The fuel parameter is fed into the present model and the gate module, which determines the importance of the fuel fraction. In addition to the original standard action loss, we also calculate an auxiliary loss using MSE, which trains the Fuel Budget Predictor for future steps. This auxiliary loss is in as a specialized component called the FuelGateModule, which essentially keeps the gate high or low depending on if the fuel is high or empty. The gate includes features that are important for exploration and goal-oriented navigation, so if fuel is limited, the drone will shift towards more direct trajectories instead of exploring the environment.
Overall, the objective of this fuel awareness constraint, in addition to the original imitation loss, is to adapt the model’s predictions to be aware of physical constraints. In the beginning, when fuel is abundant, the model will prioritize exploration and improve familiarity with new environments. When fuel is low, the model will shift towards efficient paths to maximize likelihood of reaching the end within budget.
In application, TF as a whole works because the model receives an updated ground-truth trajectory, where the actual fuel targets are generated by our FuelObservationGenerator. It computes a fuel fraction as explained above, gets included in the penalty, and contributes to the training loop update. The Seq2Seq model uses the fuel embedding to shift between exploratory or goal-seeking behavior. This is controlled by the FuelGateModule. Lastly, the CMA model takes the fuel embedding, passes it through the RNN encoder, and mathematically suppresses attention weights for scenery depending on the fuel gauge. This means like instruction embeddings associated with descriptive scenery will be filtered out compared to commands like stopping and descending.
Seq2Seq and CMA were chosen because of their compatibility with VLN tasks. Seq2Seq establishes a performance floor for how well a purely memory-based RNN handles long-horizon spatial instructions without active attention. Similarly, CMA solves the “vast search space” problem in 3D environments by mathematically aligning visual features with text tokens, preventing the drone from getting lost. Together, they represented a baseline from the original paper, and were presented in AerialVLN as models to be improved.
Results and Discussion
CMA and Seq2Seq
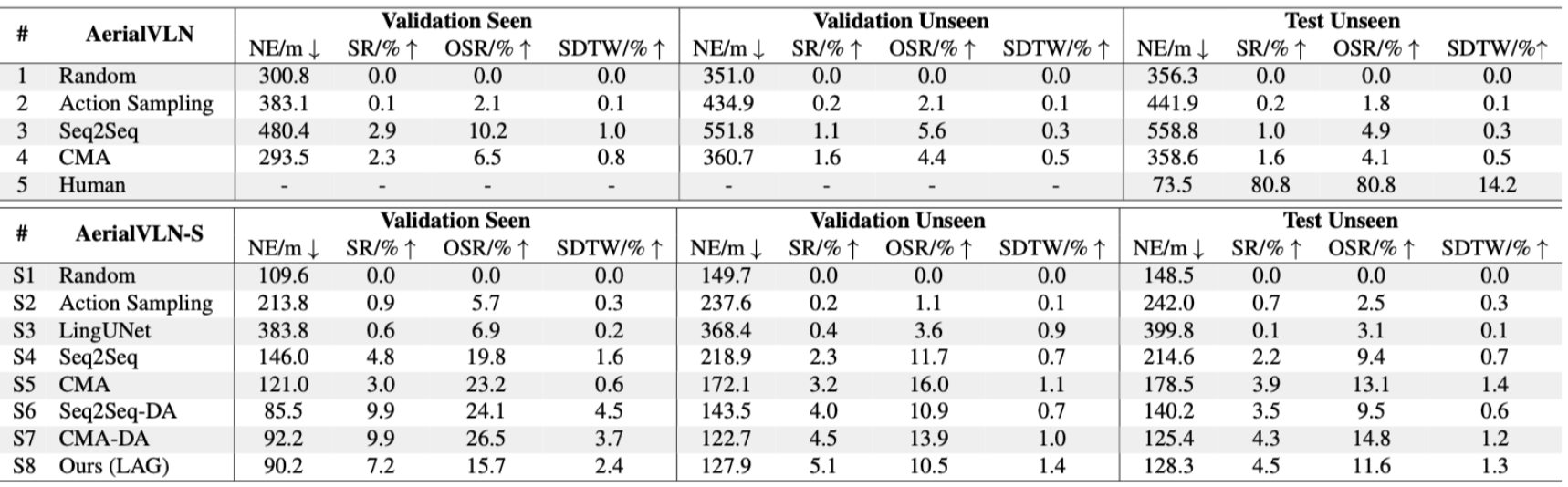
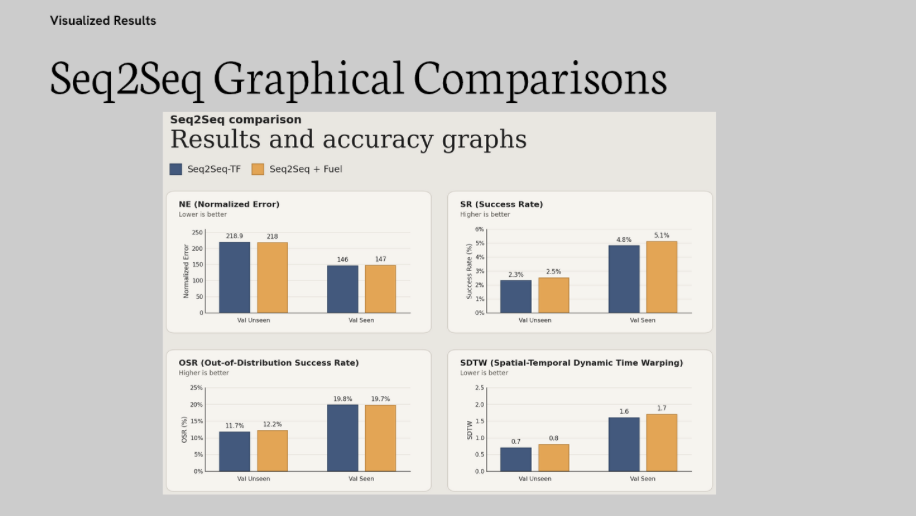
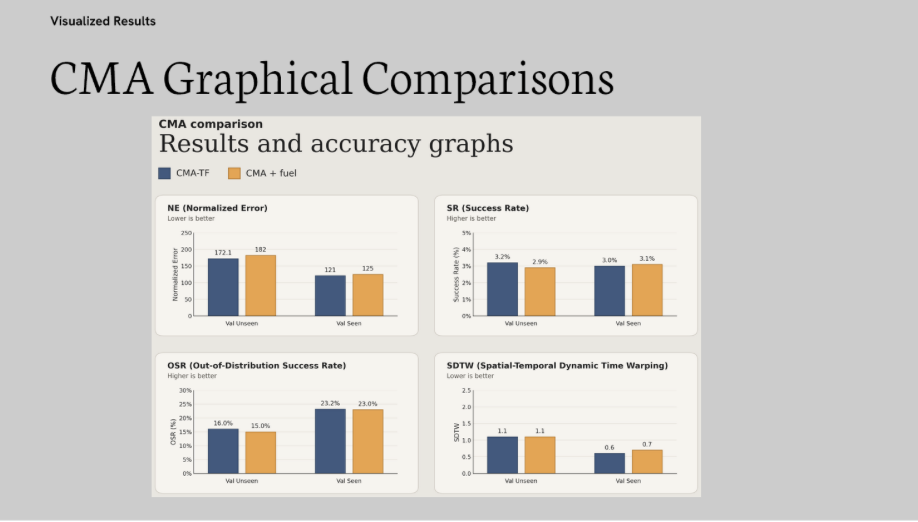
This focuses on comparing the Seq2Seq TF and CMA TF models against the fuel aware implementations that we have made. The results indicate that while the Cross-Modal Alignment (CMA) architecture is the primary driver of navigation accuracy, the fuel implementation did not produce a statistically significant impact on the baseline metrics. The performance remained consistent with the original Teaching Forcing (TF) baselines.
Architectural Impact
The transition from a standard memory-based RNN (Seq2Seq) to an attention-based alignment model (CMA) yielded the most significant improvements in spatial accuracy. In Validation Unseen environments, the CMA-TF baseline achieved a Navigation Error (NE) of 172.1m, a 21.4% reduction in error compared to the Seq2Seq-TF baseline of 218.9m.
The Success-weighted-nDTW (SDTW), which rewards both reaching the destination and following the prescribed path, saw a 57% increase, jumping from 0.7(Seq2Seq-TF) to 1.1(CMA-TF). This confirms the cross-modal attention mechanism is fundamentally better at grounding language instructions in 3D visual environments than the baseline recurrent approach.


Analysis of the Fuel Implementation
The Fuel Implementation introduces energy-aware constraints via the FuelGateModule.
- Seq2Seq Variants: In the Seq2Seq architecture, the fuel-constrained model outperformed its TF baseline across all metrics in unseen environments. The Success Rate resulted in a negligible increase from 2.3% to 2.5%, and a marginal reduction in Navigation Error by less than one meter.
- CMA Variants: In the CMA architecture, the fuel implementation resulted in a slight performance decay, with Success Rates dropping from 3.2% to 2.9% and - Navigation error increasing to 182.0m. These variances fall within the range of standard experimental noise, confirming that the fuel implementation did not fundamentally alter the agents’ navigation behavior or success metrics.

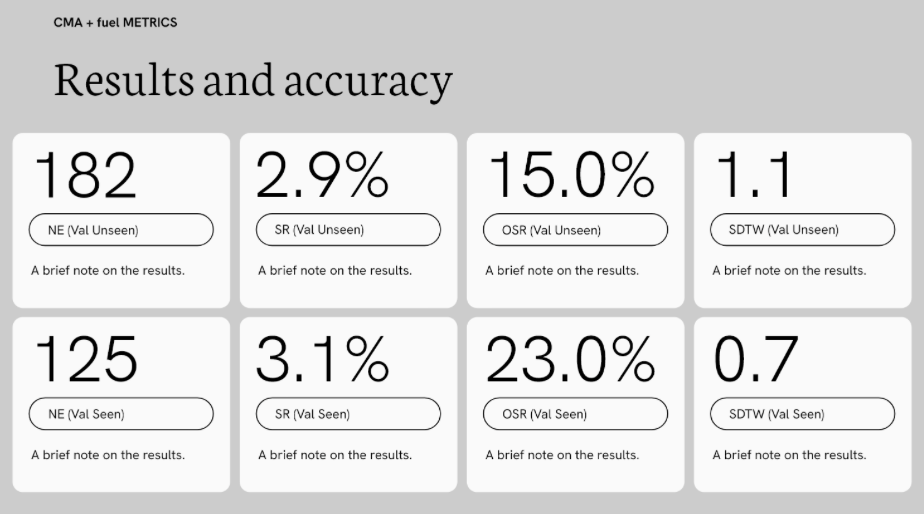
Interpretation of Marginal Impact
The lack of meaningful divergence from the base model suggests that the fuel-aware gating was likely overshadowed by the existing training dynamics
- Imitation Signal Dominance: Because models were trained via Teacher Forcing on expert trajectories, the agent primarily learned to imitate optimized paths. These ground truth paths are inherently inefficient, meaning the agent was already implicitly learning fuel-optimized behavior, leaving little room for the explicit FuelGateModule to add further value.
- Feature Saturation: In high dimensional 3D environments, visual and linguistic inputs carry significantly more weight in the policy’s decision-making over a single scalar fuel state. This policy likely prioritized visual grounding over energy constraints during the optimization process
Visualisation of successful navigation:

Green arrows show horizontal movement, such as moving forward or side to side. Blue arrows show vertical movement and turning actions, including moving up or down and turning left or right. The red circle marks the stop action. To show which landmarks match the instruction, the same colors are used for both the bounding boxes in the images and the corresponding words in the text.
More images:



Summary and Conclusion
While the transition to a CMA architecture represents a major advancement in the drone’s ability to navigate complex 3D cities, the Fuel-Aware implementation did not provide a significant performance boost. These findings indicate that for resource-aware navigation, explicit constraints may require stronger incentives-such as direct rewards in a Reinforcement Learning framework to produce a measurable impact on the agent’s policy.
Although some metrics were better, overall we were not able to get impactful resutls. This had to do with issues related to the replication. We reached out to the authors and collaborators through multiple channels, but we were ghosted most of the times, A key next step would be to investigate dataset aggregation, which was part of the original paper but not explored in this project, and which may be important for achieving stronger results.
Citations/References
[1] Liu et al. (2023). AerialVLN: Vision-and-Language Navigation for UAVs.
The primary AirVLN paper.
[2] Pereira et al. (2025). Energy-Aware Coverage Path Planner for Multirotor UAVs.
Used for the fuel modeling aspect.
[3] Morbidi, F., Cano, R., & Lara, D. (2016). Minimum-Energy Path Generation for a Quadrotor UAV.
IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden.
Other References
Morbidi, F., Cano, R., & Lara, D. (2016). Minimum-energy path generation for a quadrotor UAV. In 2016 IEEE International Conference on Robotics and Automation (ICRA), 1492–1498.
https://hal.science/hal-01276199/document
Yacef, F., Rizoug, N., Degaa, L., & Hamerlain, M. (2020). Energy-efficiency path planning for quadrotor UAV under wind conditions. In 2020 7th International Conference on Control, Decision and Information Technologies (CoDIT), Vol. 1, 1133–1138.
https://hal.science/hal-04504751/document
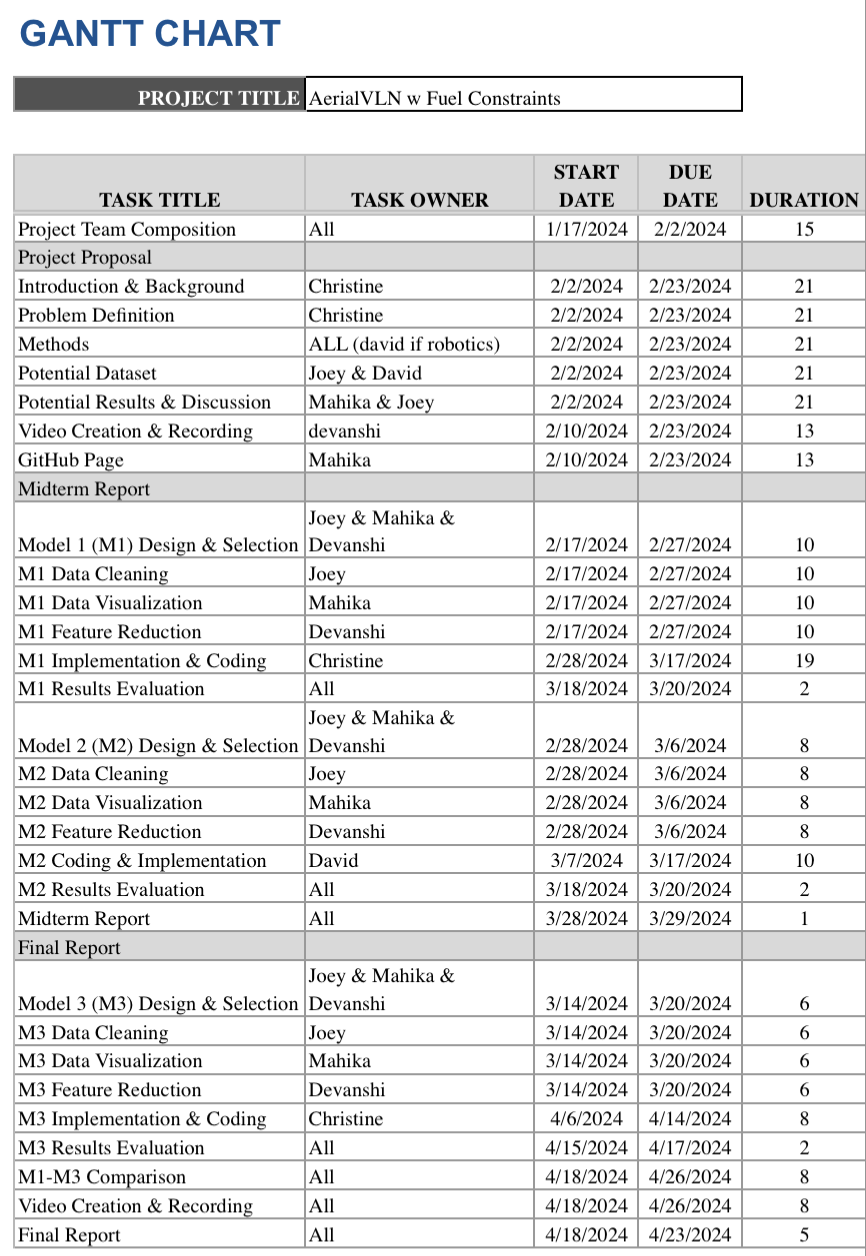
Gantt Chart:
Contribution Table:
